This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Read More
Analyse, Learn & Extract
This is approached in two ways:
As an example, by uploading PDF documents to a designated file location in Soutron, the summariser can then get to work and extract metadata including; Title, Authors, Corporate Authors, Keywords, ISBN/ISSN. It can also generate an Abstract from text within the PDF.
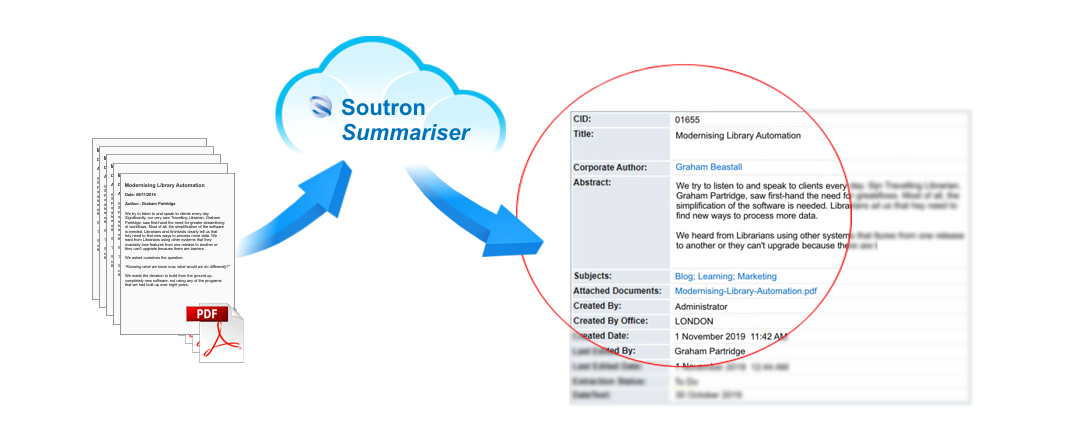
Note that any content uploaded must have the permission of the copyrighting owner to carry out this activity. Also the PDFs must be text based, not text held within an image.
The end results? The PDF collections of meetings, papers, reports, corporate information or historic records are automatically created and catalogued into Soutron ready to be published and searched.
Users of the Summariser solution have been very impressed with this new technology, in terms of labour saving and accuracy.
If you have a large collection of materials that require cataloguing, then get in touch with Soutron today so we can introduce you to Soutron Summariser. Save hours, days, weeks and perhaps even months of manual data entry.