
Lately we have seen a number of data migrations where the original data is in such a poor condition that major surgery was required when bringing it into a Soutron database.
A simple transplant of the metadata from the old to the new is typically expected but if the incoming data is allowed to be transferred without any transformation or clean up, the benefits of the new system are neutralised. User confidence in the service could suffer, simply because data is poorly structured and inconsistent and shows no improvement over the previous system. The impact of launching a new system for the library service is wasted, and the value of the investment is diminished if implementing a new system does not also incorporate the clean-up of the data itself.
Cleaning Data
We often hear prospective customers speak in terms of cleaning up their data post-migration and indeed this used to be the norm. One client initially had the idea of starting again with an empty database and were contemplating using an outside cataloguing service to re-catalogue their collection. The task facing them to clean their data seemed overwhelming.
We have built a library of scripts so that we can approach the task of normalising metadata to be of a higher quality and more consistent as part of the data migration task when implementing a new system making data more easily accessible for end users and librarians alike.
Working with Legacy Data
In large part the legacy system problems occur when data entry and data capture has been performed by different staff, using MARC tags, over a period of years. The data becomes “lost” in the database, often difficult to change once it has been added. The library staff user determines the field tag to be used. The content varies according to the preference and expertise of the member of staff. The result is inconsistent data. One person might use the tag for Place of Publication and another user might use the same tag for Publisher. It shouldn’t happen but it does. Text fields are often used for dates which include all manner of date formats including “trailing text”, all which makes indexing of dates a lottery. Authority files often need significant data cleansing because multiple variations in spelling and punctuation for the same term have been entered and no controls have been applied, typically, keyword and subject fields as well as author, editors, corporate authors, publishers etc. The result is difficulty in searching for records when inconsistent indexes are applied to data and data entry continues to introduce further non-preferred terms.
Data presented for conversion often lacks content categorisation. The types of material that are described are very broad and lack detail to allow precision recall. This sometimes arises because of lack of flexibility in the original software system or simply the old data entry system used one record template with fields for every type of material.
Clearly Defined Categories
An example is a client whose data comprised some 15,000 records categorised as Books, Journals, Images and Documents. When examined it was determined that there were some 12 different types of content, each with different record and field characteristics and importantly also different security classifications. When separated out into the appropriate categories and grouping content not only could access security be improved but also the presentation of the content was significantly improved with fewer clicks to reach documents and records.

In decades past we used Classification schemes to help identify where to shelve and find materials in a physical library. Many different Classification or Call number schemes were invented according to the needs of users and the library. These are still valuable aids but, in a world, where we now have electronic data in all kinds of different formats and types, we need to think more about how we organise that data in the database itself. That’s where having meta data accurately and consistently recorded leads to improved search, making it easier to distinguish records for the user, with greater controls over data security and access.
Analysing Data
The starting point is a careful analysis of the complete set of metadata to be stored and indexed in the new Soutron database. This includes all attachments and any additional files or data outside of the legacy library system files. We need to consider the entire data set, everything.
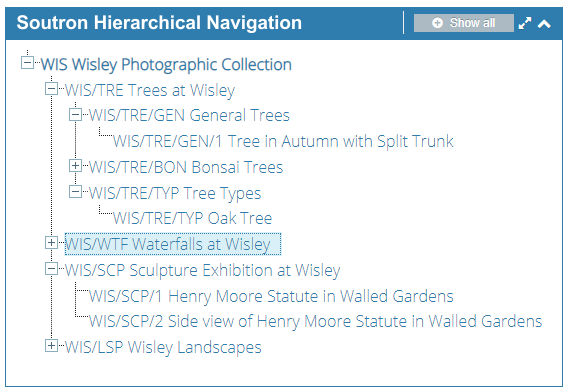 Why do we do this? An older legacy system may never have given any opportunity to manage electronic data or allow data to be related. Soutron can handle this and also provide hierarchical displays of records (see image) so while previously data could not be related, it can be in future. This leads us into examine the purpose behind the data: who uses it; how the user typically approaches finding information; what actions they perform on data etc.
Why do we do this? An older legacy system may never have given any opportunity to manage electronic data or allow data to be related. Soutron can handle this and also provide hierarchical displays of records (see image) so while previously data could not be related, it can be in future. This leads us into examine the purpose behind the data: who uses it; how the user typically approaches finding information; what actions they perform on data etc.
This guides not only the data migration but also the search portal design. It may influence how that is set up such that pre-defined searches (saved searches) can be created and presented in the portal as part of the page design such that users can then filter on data presented, making it easy for them to approach the system and to get to what they need faster.
This is where setting up categories (what we call content types and record types) can be so important. It may be that certain groups of users need access specific groups of material and the breaking down of data into categories and groups makes control over this type of data presentation so much simpler.
Below are a selection of example categories and how we display them. These are presented clearly in our Search Portal results page as ‘tabs’ which are easily selectable for users to navigate with the results below.
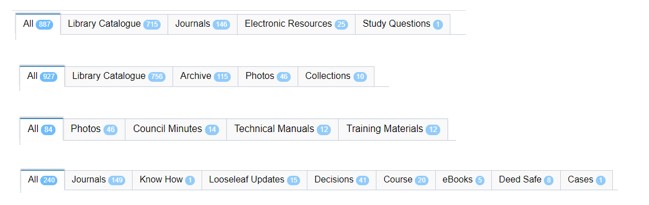
These can be labelled as you wish and made available (or hidden) from certain users who access the online resources you control.
To learn more about our cloud-based solutions and how best to present your collections and information online, contact us today.
Enter your name and email below to get our latest Soutron articles delivered straight to your Inbox.
Note: We always respect your privacy. You may unsubscribe at any time.